TechBlogHub 개발일지 03
이번 주에 개발한 것들
지난 개발일지에 이어 이번 주 작업을 정리합니다.
1. Python으로 구현되어 있던 자동 태깅 기능 → Spring Boot로 통합
기존 별도 서비스로 운영하던 Python 자동 태깅을 Spring Boot로 완전히 이전했습니다.
통합의 장점
- 배포 단순화: 2개 서비스 → 1개 서비스
- 데이터 일관성: 스키마 변경 시 한 곳만 수정
- 운영 복잡성 감소: 모니터링 포인트 축소
2. Admin API, 프론트엔드 구현
관리자를 위한 전용 시스템을 구축했습니다.
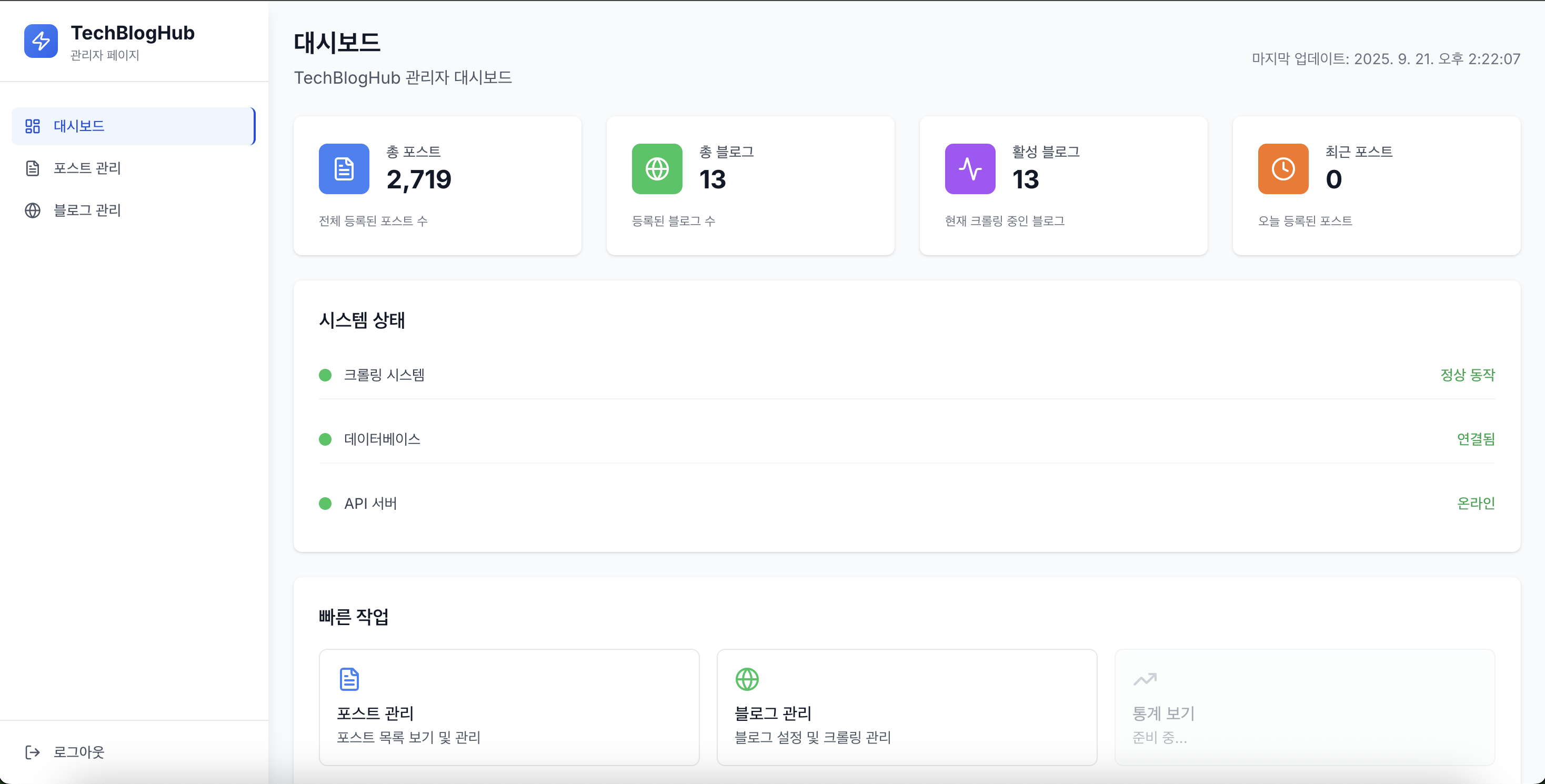
Admin 주요 기능
- 블로그 관리: RSS 피드 추가/수정/삭제, 크롤링 트리거
- 포스트 모니터링: 크롤링 상태 및 태깅 진행 현황
- 통계 조회: 태깅 성공률, 크롤링 실패율 등
Basic Auth:
- local : admin/admin123 인증
prod : variable을 설정하여 backend task가 주입받아 실행하도록 terraform 파일을 수정
1 2 3 4 5 6 7 8 9 10 11 12 13
variable "app_admin_username" { description = "App Admin UserName" type = string sensitive = true # No default value for security - must be provided via terraform.tfvars } variable "app_admin_password" { description = "App Admin Password" type = string sensitive = true # No default value for security - must be provided via terraform.tfvars }
3. RSS 크롤링 프록시 기능 추가
AWS에서 일부 RSS 피드에 접근이 불가능한 것을 파악하였고, 이를 해결하기 위해 cloudFlare에 무료 프록시 서버를 구성하였습니다. 특정 도메인에서는 프록시를 거쳐 크롤링 되도록 구현했습니다.
4. 도메인 모듈 리팩토링, 테스트 코드 작성
코드 품질 향상을 위한 대규모 리팩토링을 진행했습니다.
도메인 중심 아키텍처로 개편
- Before (기능 중심):
1 2 3 4
domain/ ├── service/ ├── model/ └── port/
- After (도메인 중심):
1 2 3 4 5 6 7 8 9 10
domain/ ├── blog/ │ ├── model/Blog.java │ ├── service/BlogService.java │ └── usecase/BlogUseCase.java ├── post/ ├── tagging/ │ ├── auto/ # LLM 자동 태깅 │ └── manual/ # 수동 태깅 └── crawling/
- Before (기능 중심):
AutoTaggingService 책임 분리 하나의 큰 서비스를 역할별로 분리:
- AutoTaggingService: 전체 프로세스 조율
- TaggingProcessor: 실제 태깅 로직
- TagPersistenceService: 태그 저장
- RejectedItemService: 거부된 항목 관리
테스트 코드 작성
- 도메인 모델 테스트
- 서비스 레벨 테스트
- AutoTaggingServiceTest: Mock을 통한 서비스 로직 검증
- RssCrawlerServiceTest: RSS 크롤링 프로세스 테스트
- BlogServiceTest: 블로그 관리 비즈니스 로직 테스트
- 인프라 레벨 테스트
- HttpRssFeedAdapterTest: RSS 파싱 로직
- ProxyUrlResolverTest: 프록시 URL 생성 로직
- RetryHandlerTest: 재시도 메커니즘
리팩토링 효과
- 코드 이해도 향상: 도메인별 응집도 증가
- 유지보수성: 변경 영향 범위 명확화
- 확장성: 새 도메인 추가 용이
- 안정성: 테스트 커버리지 대폭 향상
5. 태깅 개선 및 기능 확장을 위한 AI Agent 개발중…
현재 태깅시스템의 문제점 현재 태깅 시스템은 RSS로 수집된 title, content(짧은 글) 만으로 태깅을 진행하고 있습니다.
태그 또한 제가 사전에 정의한 약 200개의 태그만 사용하고 있어서, 적절하지 않은 태깅이 상당수 존재합니다. 이를 개선하기 위해 글의 전문을 수집하고, 이를 통해 tagging을 진행하려고 합니다.AI Agent 개발 방향 우선 정확도 높은 태깅을 제공하기 위해선 글의 전문이 필요했습니다.
글의 전문을 가져오기 위해 document_loaders 중 PlaywrightURLLoader를 사용할 예정입니다.
html을 전부 가져온 후 text로 파싱하기 위해 document_transformers 중 MarkdownifyTransformer를 사용하려고 합니다.
url을 통해 markdown으로 크롤링 해주는 서비스가 존재하긴 하지만, 유료이기에 제가 직접 조합해서 구현하려고 합니다.
https://www.firecrawl.dev/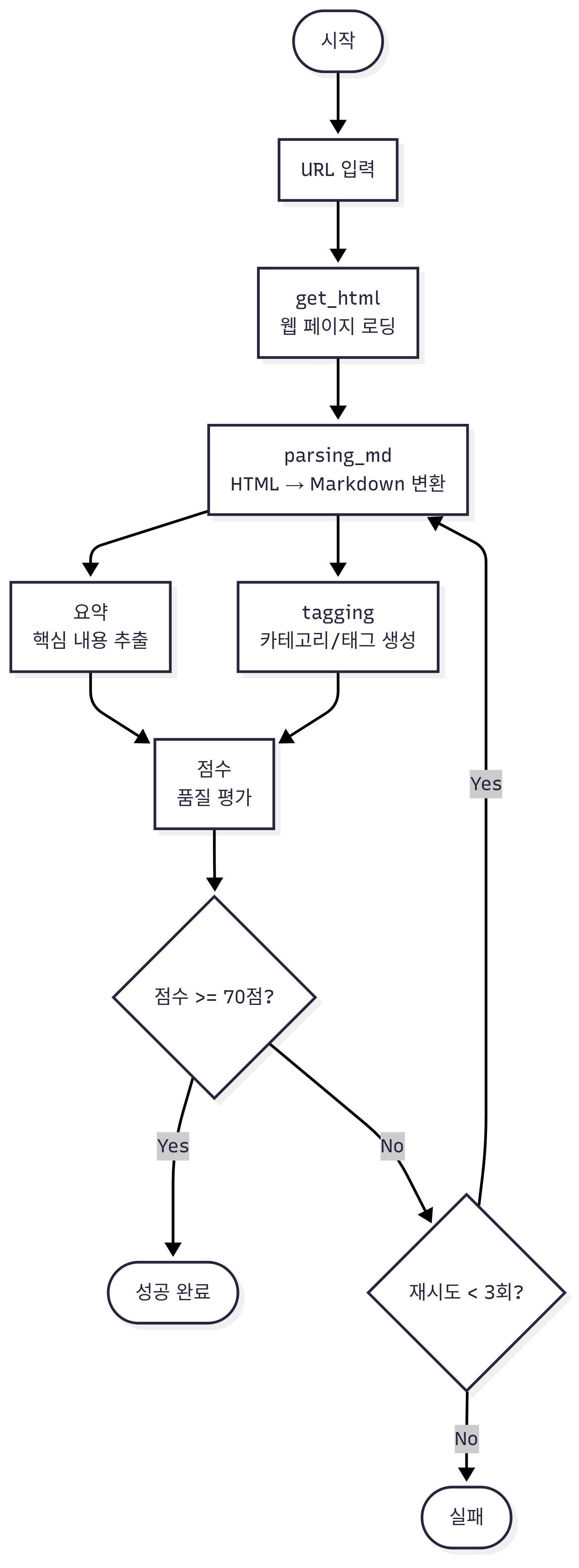
예전에 인프런에서 구매했던 강의를 끝까지 듣고 AI Agent를 개발해 보려고 합니다.
이 링크를 통해 구매하시면 제가 수익을 받을 수 있어요. 🤗 https://inf.run/dw21U
이번 주의 배움
1. 모놀리스의 힘
Python 크롤러를 Spring Boot로 통합하면서 느낀 점:
- 운영 단순화: 하나의 서비스로 모든 것을 관리
- 개발 속도: 스키마 변경, 배포, 디버깅이 훨씬 빠름
- 적절한 분리: 마이크로서비스가 항상 답은 아니다
2. 도메인 주도 설계의 위력
- 코드 가독성: 관련 기능이 한 곳에 모여 있어 이해하기 쉬움
- 변경 용이성: 특정 도메인 변경 시 영향 범위가 명확
- 팀 협업: 도메인별로 담당자를 나누기 좋음
3. 테스트 코드의 안전망
대규모 리팩토링을 진행하면서 테스트 코드 덕분에 안전하게 변경할 수 있었습니다.
다음 주 계획
- AI Agent 완성: Playwright 기반 웹 추출 시스템 통합
- 검색 기능 고도화: Elasticsearch 도입 검토
- 사용자 기능: 회원가입, 북마크, 개인화 추천
- 모니터링 강화: 시스템 메트릭 및 알림 시스템
마치며
이번 주는 “통합과 정리의 주간”이었습니다.
분산되어 있던 기능들을 하나로 모으고, 코드를 체계적으로 정리하면서 앞으로의 개발을 위한 탄탄한 기반을 마련했습니다.
특히 AI Agent 개발을 통해 태깅 품질을 한 단계 더 끌어올릴 수 있을 것 같아 기대됩니다!