TechBlogHub 개발일지 02
이번 주에 개발한 것들
지난 개발일지에 이어 이번 주 작업을 정리합니다.
우선! 1차 배포를 마쳤습니다 🎉 → 기술 블로그 모음
도메인을 구매할 때 오타가 나서 원래 원했던 techbloghub.kr 대신 teckbloghub.kr을 쓰게 되버린… 😂 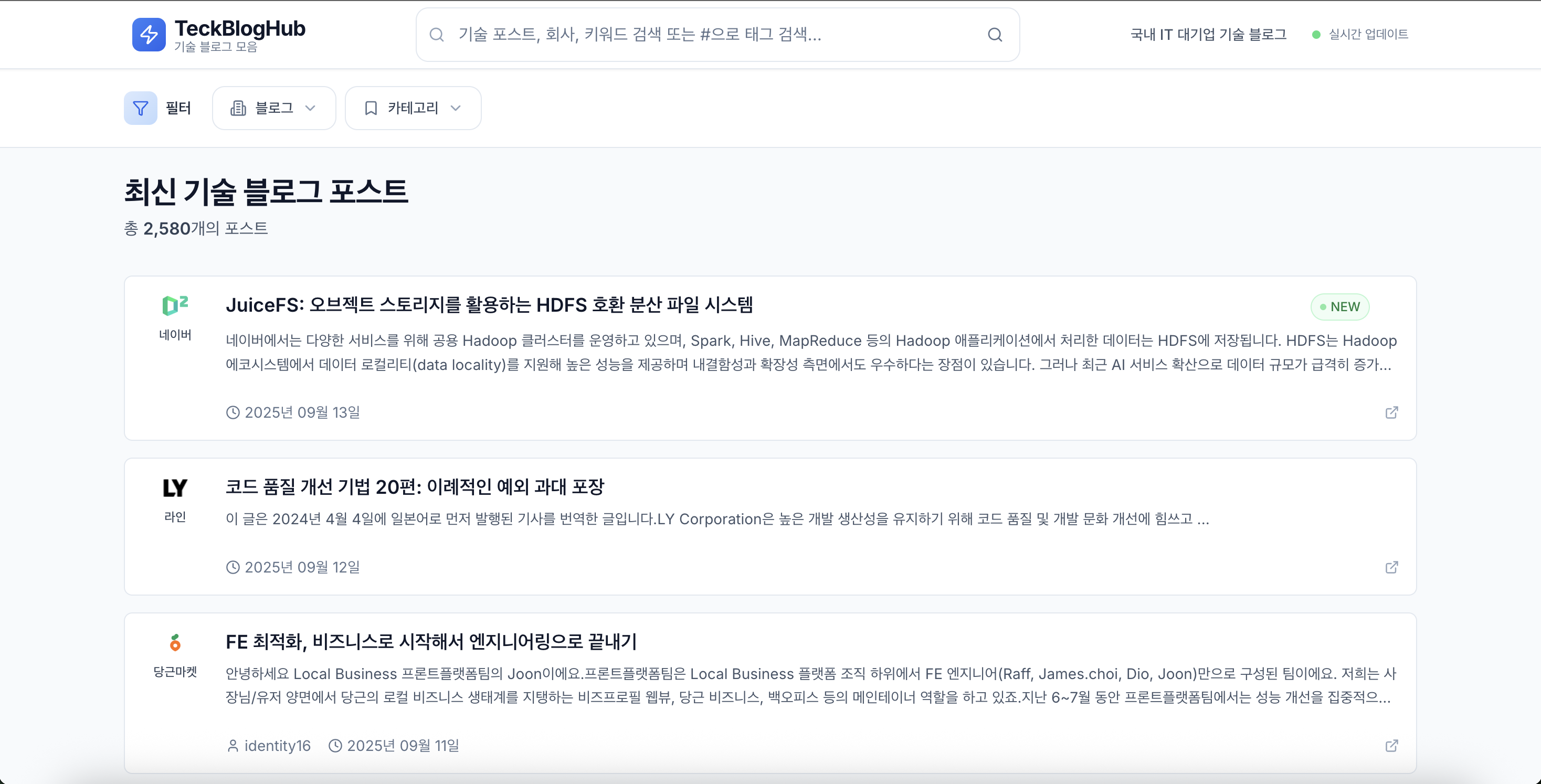
배포 과정
배포는 frontend, backend 모두 ECS로 구성했고, 인프라 관리는 Terraform으로 진행했습니다.
개인 프로젝트지만, 이전 회사 면접에서 Terraform 얘기가 나온 적이 있어 이번 기회에 직접 써봤습니다.
AWS Console
- 장점: 직관적인 UI, 시각적 모니터링, 쉬운 학습
- 단점: 클릭 실수 위험, 설정 기억 어려움
Terraform
- 장점: IaC(Infrastructure as Code), 버전 관리, 자동화
- 단점: 진입장벽 높음, 복잡성
콘솔은 익숙하긴 하지만 업데이트가 잦아 혼란스러울 때가 많습니다. 반면 Terraform은 terraform output으로 필요한 값을 정의하거나 terraform destroy로 자원을 정리할 수 있다는 점이 가장 매력적이었습니다.
또 코드로 관리하니 “언제 설정이 바뀌었는지”를 추적하기 쉽다는 점도 큰 장점이었습니다.
RSS 크롤링: 백엔드에서 관리
원래는 python-crawler를 Lambda로 옮기려 했습니다.
Lambda에선 라이브러리 제약, Layer 관리, VPC 연결 문제 등이 발목을 잡았습니다.
하루 1회 실행을 위해 퍼블릭 서브넷을 만드는 것도 과하다고 판단했습니다.
결국 백엔드에서 스케줄링하는 방식으로 바꿨습니다.
이 덕분에 DB 스키마가 바뀔 때 크롤러까지 수정할 필요 없이 백엔드만 고치면 되니 유지보수 범위가 줄어드는 장점도 생겼습니다.
또한, RSS가 백엔드로 흡수되면서 batch 모듈과 output-web 모듈도 추가했습니다.
태그 검색 UX 개선
현재 태그는 200개 이상, 그룹은 27개나 됩니다. 그대로 보여주기엔 UX가 좋지 않았습니다.
그래서 Slack/Notion/Jira에서 쓰는 방식처럼, 검색창에 #을 입력하면 자동완성 dropdown이 뜨고 선택 시 chip으로 추가되는 방식을 채택했습니다. 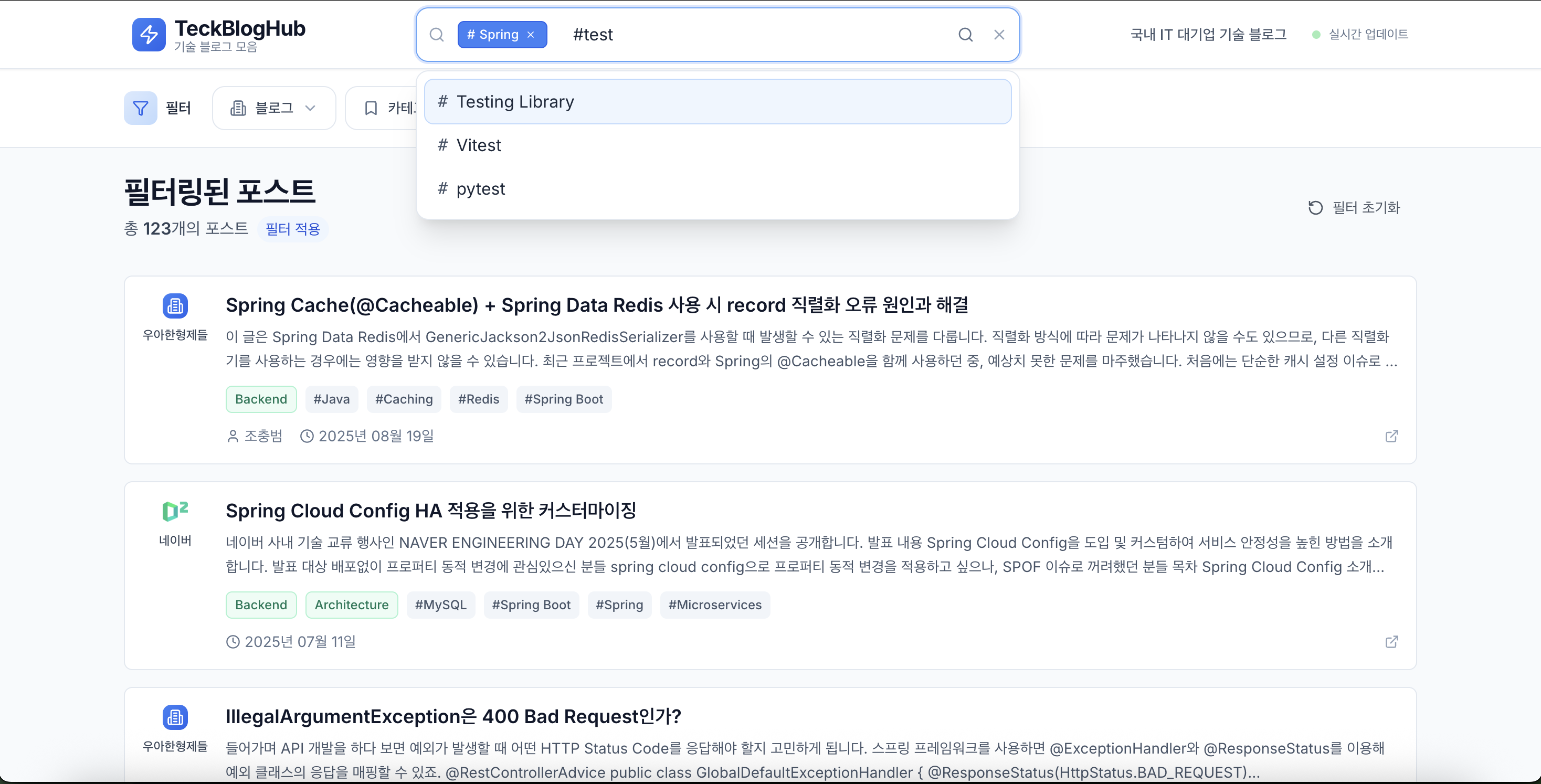
장점
- 인지 부하 감소 → 필요할 때만 태그 검색
- 빠른 접근성 →
#입력 → 자동완성 → chip 생성 - 공간 절약 → 태그 목록이 UI를 차지하지 않음
- 익숙한 UX 패턴 → 러닝커브 낮음
고려할 점
- 발견성 부족: 모든 태그를 보이지 않으니 추천 태그/최근 사용 태그를 먼저 노출하는 방안 필요
- 태그 그룹 활용성:
#infra:,#security:같은 prefix 검색 고려 - 멀티 셀렉트 UX: 태그 선택 후 입력창 포커스를 유지해 연속 입력 가능하게
태그 구조는 아직 유동적입니다. 현재는 LLM을 이용한 태깅을 쓰지만 정확도가 부족해 다른 방안도 검토 중입니다.
자잘한 개선들
URL 중복 체크 버그 수정
backfill 데이터에 한글 URL이 있어 퍼센트 인코딩된 URL과 중복 인식이 안 되던 문제
→normalizedUrl생성(인코딩 + 마지막/제거)으로 해결백엔드 n+1 쿼리 최적화
post와 관련된 tag, category 조회 시fetch join과batch size로 개선
지금까지의 배움
인프라는 어렵다
즉각적인 피드백이 없고 테스트도 쉽지 않아 시행착오가 많았다.
도메인도techbloghub.kr인 줄 알고 네임서버를 옮겼는데, 사실은teckbloghub.kr을 구매했을 때처럼…
테스트 가능한 부분은 반드시 테스트 코드로 보완해야겠다고 느꼈다.Cloud ≠ Local
로컬에서는 잘 되던 크롤링이 AWS에서는 안 된다거나, 로컬 캐싱 때문에 내 PC에서만 잘 되는 경우도 있었다.
환경 차이에 유연하게 대응할 수 있는 코드 작성이 필요하다.
앞으로의 계획
- 태깅 로직 백엔드 편입
- 하루 1회 실행을 위해 별도 서비스 배포는 비효율적
org.springframework.ai:spring-ai-openai로 Spring 내부에서 LLM 호출
- 회원 기능 추가
- 로그인, 북마크 → 개인화 추천으로 확장
- 데이터 확장
- 더 많은 블로그 크롤링
- 태그/카테고리 지속 개선
- 추천 시스템 고도화
- 단기: 태그 + Elasticsearch
- 중기: TF-IDF / Embedding 실험
- 장기: 사용자 행동 기반 개인화 추천
마치며
이번 주의 가장 큰 교훈은 “인프라는 어렵다”였습니다.
예전엔 “내 PC에선 잘 되는데?” 짤을 보며 웃었지만, 이제는 웃기만 할 수 없는 상황이네요.

결국 테스트 코드가 가장 확실한 안전망이라는 걸 다시 느꼈습니다. 앞으로는 테스트를 더 신경 쓰며 코드를 작성하려 합니다.