TechBlogHub 개발일지 01
도입
국내외 많은 IT 기업들이 기술 블로그를 운영하고 있습니다.
저도 여러 곳을 구독하다 보니, “한 곳에서 모아보고, 관련 글도 바로 찾아볼 수 있으면 좋겠다” 는 생각이 들었습니다.
이미 TechBlogPosts, NewCodes 같은 서비스가 있긴 합니다. 하지만 대부분 단순 나열에 가까웠고, 저는 분류와 관련 글 추천까지 제공하는 걸 목표로 삼았습니다.
백엔드 개발자로서 부족한 부분은 AI 도구들의 도움을 받기도 했습니다.
프로젝트 개요
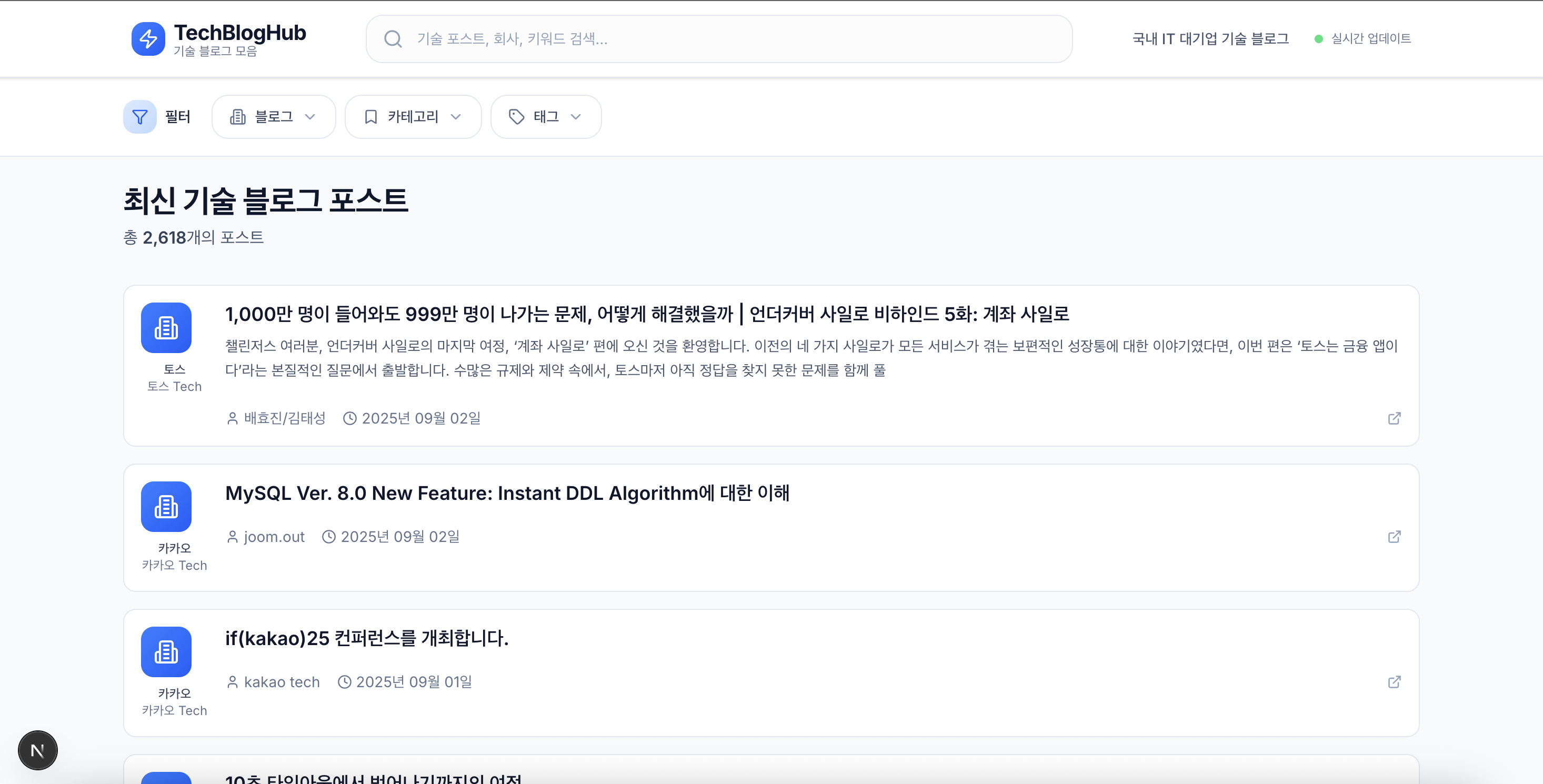
- 시작일: 2025-08-28 ~
- 개발자: 혼자 (사이드 프로젝트)
- 목표: 기술 블로그를 수집하고, 카테고리와 태그로 분류해 비슷한 글을 추천하는 플랫폼 만들기
기술 스택 & 아키텍처 선택
- Frontend: Next.js 15, TypeScript, React-Query, TailwindCSS
- Backend: Spring Boot 3.2 (헥사고날 아키텍처), Java 21, PostgreSQL, JPA, QueryDSL
- 크롤링 / 태깅: FastAPI, SQLArchemy, openai, BeautifulSoup4 (추후 AWS Lambda 이전 예정)
👉 사실 기술 스택은 “최적”보다는 익숙함과 개발 속도를 우선으로 정했습니다.
Next.js는 SEO와 CSR/SSR 하이브리드가 마음에 들었고, Spring은 제가 제일 잘 다루는 프레임워크라 빠르게 시작할 수 있었습니다.
크롤링 구현 — 생각보다 험난했던 길
처음엔 단순했습니다.
“RSS가 있으니 쉽게 가져오겠지?” → 최신 글은 가능했습니다.
문제는 과거 글.
RSS에는 최근 글 몇 개만 포함돼 있어서, 결국 직접 크롤링을 구현해야 했습니다.
시행착오
- 블로그별로 API 구조가 제각각이라 개발자 도구 열고 네트워크 탭 뜯어보기의 연속
- Medium은 SSR + GraphQL 구조라서 “이걸 어떻게 긁지…?” 한참 헤맸습니다
→ BeautifulSoup4 + GraphQL 요청 분석으로 겨우 해결
그리고 여기서 솔직히 좀 고민이 있었습니다.
“공식 문서화된 API도 아닌데, 네트워크 탭에서 본 요청을 직접 호출해도 되는 걸까?”
- 트래픽은 적고, 개인 프로젝트 수준이라 큰 문제는 없다고 판단했지만
- 서비스가 커지면 법적/윤리적으로 애매할 수 있다는 생각은 여전히 남아 있습니다.
이 고민은 앞으로도 계속 가져갈 것 같습니다…
현재까지는 9개 블로그, 2,618개 글 수집 완료.
관련 글 추천 — 고민의 갈림길
“관련 글을 어떻게 보여줄까?” 이 질문이 프로젝트의 핵심 난제였습니다.
고려했던 방법
태그 기반 추천
- LLM이 글 제목/요약을 분석 → 태그 생성
- 장점: 구현 간단, 사람이 이해하기 쉬움
- 단점: 태그 품질에 따라 정확도 좌우
Elasticsearch 유사도 검색
- Multi-Match Query, More Like This 등 활용
- 장점: 성능, 안정성
- 단점: 단순 키워드 매칭, 의미론적 유사도 부족
Text Embedding 기반 추천
- LLM Embedding + 벡터 DB
- 장점: 표현 달라도 의미 기반 유사도 가능
- 단점: 비용 부담, 운영 복잡
최종 선택
MVP 단계에서는 태그 기반 추천.
- 비용: Embedding보다 훨씬 저렴
- 속도: 구현 빨랐음
- 유지보수: 태그 체계만 관리하면 됨
태그 시스템 — 또 다른 난관
1차 시도: 순수 LLM 태깅
- 글 제목 + 요약을 넣고 “태그 0~8개 생성” 요청
- 결과: 100개 글 → 태그 중복률 0% (!)
- 원인:
- LLM이 매번 새로운 태그를 창조
- 대소문자 불일치 (
Javascriptvsjavascriptvsjs)
- 결론: 관리 불가
2차 시도: 계층형 태그 사전
- 25개 태그 그룹 정의
- 약 500개 하위 태그 구축
- 프로세스:
- LLM이 태그 후보 생성
- 기존 태그 사전에 매핑
- 매핑 실패 →
rejected_tag로 저장 - rejected_tag가 많이 쌓이면 정식 태그로 승급
-> 이렇게 해서 LLM의 창의성을 완전히 죽이지 않으면서도, 통제 가능한 구조를 갖출 수 있었습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Please analyze this tech blog post and extract relevant tags and categories.
Title: {title}
Content: {content}
AVAILABLE TAGS (MUST USE ONLY FROM THIS LIST):
{tag_groups_str}
AVAILABLE CATEGORIES (MUST USE ONLY FROM THIS LIST):
{categories_str}
Please provide your response in the following JSON format:
tags
STRICT GUIDELINES:
- **MANDATORY**: ONLY use tags from the "AVAILABLE TAGS" list above - DO NOT create new tags
- **MANDATORY**: ONLY use categories from the "AVAILABLE CATEGORIES" list above
- Provide 0-8 most relevant tags that best represent the technical content
- Provide 1-3 most relevant categories that best fit the post
- Use EXACT naming from predefined lists (case-sensitive)
- If the post is in Korean, provide English tags and categories from the lists
- Focus on technical aspects and concrete technologies mentioned in the content
- If you cannot find appropriate tags from the predefined list, use fewer tags rather than creating new ones
Return only the JSON response, no other text.
지금까지의 배움
- 기획이 제일 어렵다
코드보다 “어떻게 분류할 것인가?”가 더 큰 난제였습니다. - MECE(서로 배타적이고 전체를 포괄하는) 분류는 이상일 뿐
- Docker는 DevOps인가, Infrastructure인가?
- “프론트엔드 성능 최적화”는 Frontend인가, Architecture인가?
결국 기술은 경계가 흐려져 있어서, 완벽히 나눌 수가 없습니다.
- LLM은 만능이 아니다
처음엔 “LLM이 태깅 다 해주겠지” 생각했지만,
결국 사람이 통제할 체계를 만들지 않으면 혼란만 커졌습니다. - 완벽보다는 실행
일단 태그 기반으로 구현하고, rejected_tag로 점진적으로 발전시키는 접근이 현실적이었습니다.
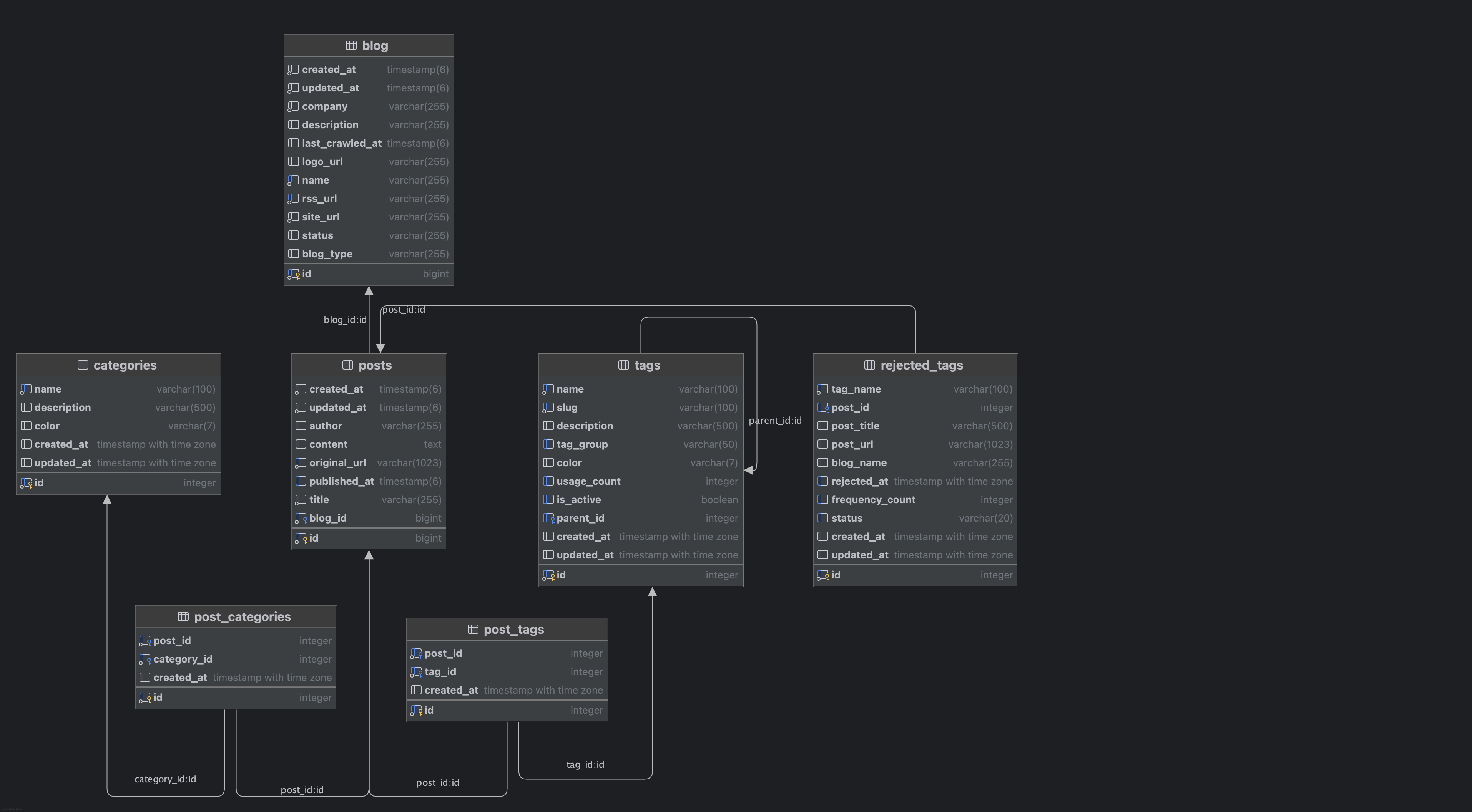
앞으로의 계획
- Admin 시스템 개발
- 배포 구조: Admin과 Application을 별도 배포
- Admin: 내부 관리용, 태그/카테고리/크롤링 현황 모니터링 전용
- Application: 일반 사용자용, 글 탐색 및 추천 기능 제공
- Backend: 헥사고날 아키텍처 기반 멀티 모듈 구성 → Admin과 Application 모듈을 분리해 독립 배포 가능
- Frontend: 모노레포 아키텍처 기반 → Admin과 Application 프로젝트를 같은 레포에서 관리, 공통 컴포넌트 재사용 용이
- 목표:
- 태그 관리, rejected_tag 승급 프로세스 구현
- 크롤링 진행 상황 모니터링
- 유지보수 및 확장 용이성 확보
- 배포
- AWS EC2 프리티어 활용 → 초기 MVP 서비스 운영
- AWS Lambda로 크롤러 이전 예정 → 서버리스로 비용 절감
- Supabase 등 DB/인증 기능 실험 고려
- 회원 기능 추가
- 로그인, 북마크 기능 → 사용자 정보 기반 추천으로 확장
- 개인화 추천 → 장기 목표: 내가 본 글, 좋아요/북마크 데이터를 활용
- 데이터 확장
- 더 많은 블로그 크롤링
- 태그/카테고리 지속 개선
- 추천 시스템 고도화
- 단기: 태그 + Elasticsearch 조합
- 중기: TF-IDF / Embedding 실험
- 장기: 사용자 행동 기반 개인화 추천
마치며
이번 프로젝트를 하면서 깨달은 건, “기술보다 기획이 어렵다”는 점이었습니다.
분류 기준을 어떻게 잡을지, 어떤 방식으로 추천할지를 고민하는 게 Spring 코드 몇 천 줄 짜는 것보다 훨씬 힘들었습니다.
아직 미완성이지만, “완벽하지 않아도 실행해보자” 라는 마음으로 계속 나아가 보려고 합니다.