WIL Spring Cacheable
사내 서비스가 커지면서 트래픽이 점점 늘어나고 있다. 덕분에 일이 많아졌지만, 쉽게 경험할 수 없는 이슈라고 생각하며 즐겁게 일하고 있다. 많은 부분을 개선할 수 있겠지만, 내가 맡은 부분은 RDS의 CPU 사용률이다. 학교를 대상으로 하는 서비스다보니 주중 오전 8시부터 오후 4시까지는 DB에 꽤나 높게 부하가 걸린다. 이번주 WIL은 이러한 부하를 줄이기 위한 여러가지 시도들을 기록해본다.
CPU 사용량을 줄이기 위한 방법은 크게 다음과 같다.
- 인덱싱 최적화
- 쿼리 최적화
- 스케일링
- 캐싱
- DB 파라미터 조절
1번, 3번, 5번은 DB를 수정해야 하는 것이기에 사원으로서 감당할 수 있는 범위 밖의 일이었다. 그리고 이미 설정이 되어 있는 부분이 많고, 추가적으로 설정함으로써 CPU 사용량을 줄이는 것에는 한계가 있다고 판단했다. 내가 할 수 있는 것은 쿼리 최적화와 캐싱이었고, 두 가지 방법 모두 다 사용하면 더욱 좋았겠지만 우선 캐싱을 선택하였다.
Spring 에서 Cache 사용하기
캐시 설정 추가
@Cacheable annotation을 사용하기 위해서는 설정이 필요하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
@Configuration
@EnableCaching
public class RedisConfig {
@Value("${spring.redis.host}")
private String redisHost;
@Value("${spring.redis.port}")
private int redisPort;
@Bean
public RedisTemplate<String, ?> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, ?> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(new GenericJackson2JsonRedisSerializer());
return redisTemplate;
}
@Bean
public RedisCacheManager redisCacheManager(RedisConnectionFactory redisConnectionFactory) {
PolymorphicTypeValidator typeValidator = BasicPolymorphicTypeValidator
.builder()
.allowIfSubType(Object.class)
.build();
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.activateDefaultTyping(typeValidator, ObjectMapper.DefaultTyping.NON_FINAL);
objectMapper.registerModule(new JavaTimeModule()); // LocalDateTime serialize를 하기 위한 모듈 설정
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration
.defaultCacheConfig()
.serializeKeysWith(
RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer())
)
.serializeValuesWith(
RedisSerializationContext.SerializationPair.fromSerializer(
new GenericJackson2JsonRedisSerializer(objectMapper)
)
);
return RedisCacheManager
.RedisCacheManagerBuilder
.fromConnectionFactory(redisConnectionFactory)
.cacheDefaults(redisCacheConfiguration)
.withCacheConfiguration(
RedisCacheKey.STUDENT_DASH_BOARD,
redisCacheConfiguration.entryTtl(Duration.ofHours(6L))
) // TTL 설정
.build();
}
@Bean
public RedisConnectionFactory redisConnectionFactory() {
return new LettuceConnectionFactory(redisHost, redisPort);
}
}
cache를 관리해 줄 CacheManager를 빈으로 등록한다.
@Cacheable
@Cacheable 어노테이션을 메소드에 적용하면, Spring은 첫 번째 메소드 호출 시 반환값을 캐시에 저장하고, 이후 동일한 인수로 메소드를 호출할 때 메소드를 실행하지 않고 캐시된 값을 반환한다.
1
2
@Cacheable("books") // value = "books" 와 동일
public Book findBook(ISBN isbn) {...}
- value : 사용할 캐시의 이름을 지정한다. 배열 형태로 여러 캐시 이름을 지정할 수 있다.
- key : 캐시에서 항목을 식별하는 데 사용할 키를 지정한다. 기본적으로 메소드의 매개변수 값을 기반으로 키를 생성한다.
- condition : 표현식이
true를 반환하는 경우에만 캐싱을 적용한다. 예를 들어, 특정 조건 아래에서만 결과를 캐시하고 싶을 때 사용할 수 있다. - unless : 표현식이
true를 반환하는 경우 결과를 캐시하지 않는다. 예를 들어, 반환값이 특정 조건을 충족하는 경우에는 캐싱하지 않도록 설정할 수 있다.
1
2
3
4
5
6
7
8
@Cacheable(
cacheManager = "redisCacheManager",
value = RedisCacheKey.Book,
key = "'query:' + #query + ':authorId:' + #authorId + ':paramsHash:' + T(java.util.Objects).hash(#pageable.pageNumber, #pageable.pageSize, #pageable.sort)",
condition = "@redisCacheUtils.isRedisAvailable()"
unless = "#result==null"
)
public Page<BookDto> getBookPage(String query, Long authorId, Pageable pageable) {...}
condition 조건을 통해 redis가 살아 있을때에만 캐싱하도록 설정
unless 조건을 통해 결과가 null이 아닌 경우에만 캐싱하도록 설정
@CachePut
캐시에 값을 저장하는 용도로 사용한다. 이 어노테이션을 사용하면 메소드가 호출될 때마다 메소드의 결과를 캐시에 강제로 추가하거나 업데이트 한다. 이는 메소드의 실행을 방해하지 않으면서, 캐시에 저장된 데이터를 최신 상태로 유지하고자 할 때 유용하다.
1
2
3
4
5
@CachePut(value = "userCache", key = "#user.id")
public User updateUser(User user) {
userRepository.save(user);
return user;
}
@CachePut은 왜 쓸까? 데이터베이스나 다른 데이터 소스에 데이터를 업데이트하고, 해당 변경사항을 즉시 캐시에 반영해야 할 때. 캐시된 데이터가 항상 최신 상태를 유지하도록 보장.
@CacheEvict
캐시의 값을 제거하는데 사용한다. 이 어노테이션은 캐시된 데이터를 명시적으로 삭제하거나 무효화할 필요가 있을 때 유용하며, 데이터의 일관성을 유지하고 오래된 또는 더 이상 필요 없는 데이터로 인한 리소스 낭비를 방지할 수 있다.
1
2
3
4
@CacheEvict(value = "users", key = "#userId")
public void deleteUser(String userId) {
userRepository.deleteById(userId);
}
- value : 사용할 캐시의 이름을 지정한다. 배열 형태로 여러 캐시 이름을 지정할 수 있다.
- key : 캐시에서 제거할 특정 항목의 키를 지정한다.
SpEL(Spring Expression Language)을 사용하여 동적으로 키를 생성할 수 있다. - allEntries:
true로 설정하면 지정된 캐시의 모든 항목을 제거한다. 이 속성이true일 때key속성은 무시된다. - beforeInvocation: 이 속성이
true로 설정된 경우, 메소드 실행 전에 캐시에서 항목을 제거한다. 기본값은 false이며, 이 경우 메소드 실행 후에 항목이 제거된다. - condition: 캐시 제거가 수행될 조건을 지정할 수 있다. 이 역시 SpEL을 사용하여 설정할 수 있으며, 조건이
true일 때만 캐시에서 항목이 제거된다.
캐시의 TTL은 얼마가 적당한가?
캐시 데이터의 TTL(Time To Live)을 결정하는 것은 여러 요소를 고려해야 한다.
데이터의 신선도
데이터가 얼마자 자주 변경되는지 고려해야 한다. 자주 업데이트 되는 데이터들은 낮은 TTL로 사용자에게 최신의 정보를 제공해한다. 또한 사용자가 최신 정보를 필요로 하는 경우 캐시를 삭제하고 다시 저장해야 한다.
시스템 성능 및 부하
높은 캐시 히드율을 유지하기 위해 긴 TTL을 사용할 수 도 있다. 하지만 이는 데이터 신선도와 상충된다. 또한 서버 부하를 줄이기 위해서 TTL을 늘릴 수 있다.
💡 캐시 히트율(Cache Hit Rate)
캐시 시스템에서 요청된 데이터가 캐시에 존재하여 바로 접근할 수 있는 비율.
캐시의 성능과 효율성을 평가. 캐시 히트율 = (캐시 히트 수 / 총 캐시 요청 수) * 100자원 제약조건
사용 가능한 캐시 메모리가 제한적일 경우, 너무 많은 데이터를 캐시에 보관하면 메모리 부족 문제가 발생할 수 있다.
캐시 적용 후
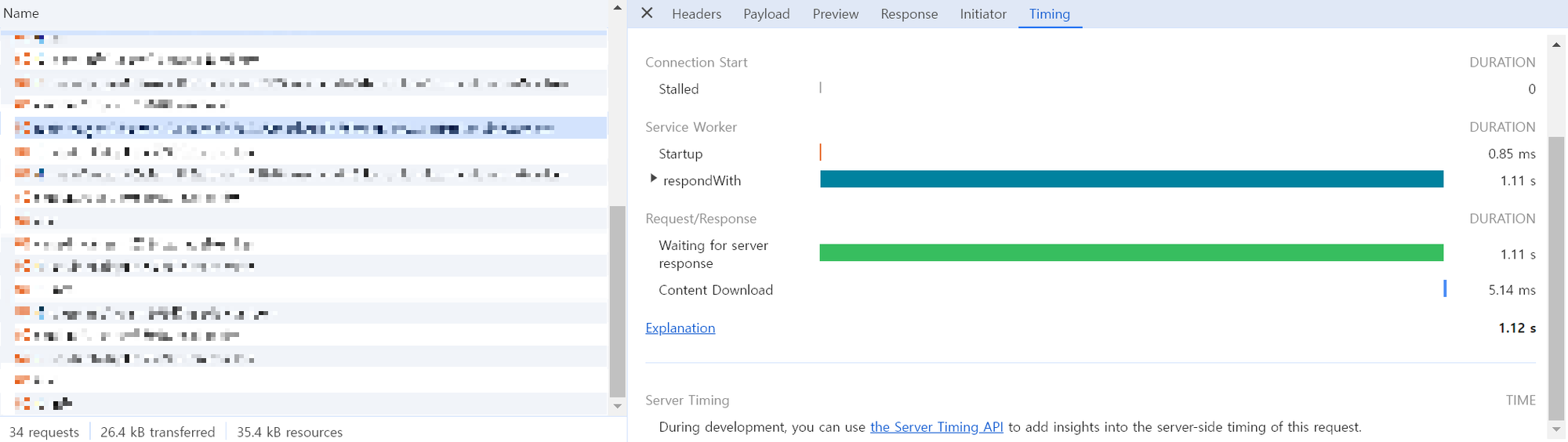
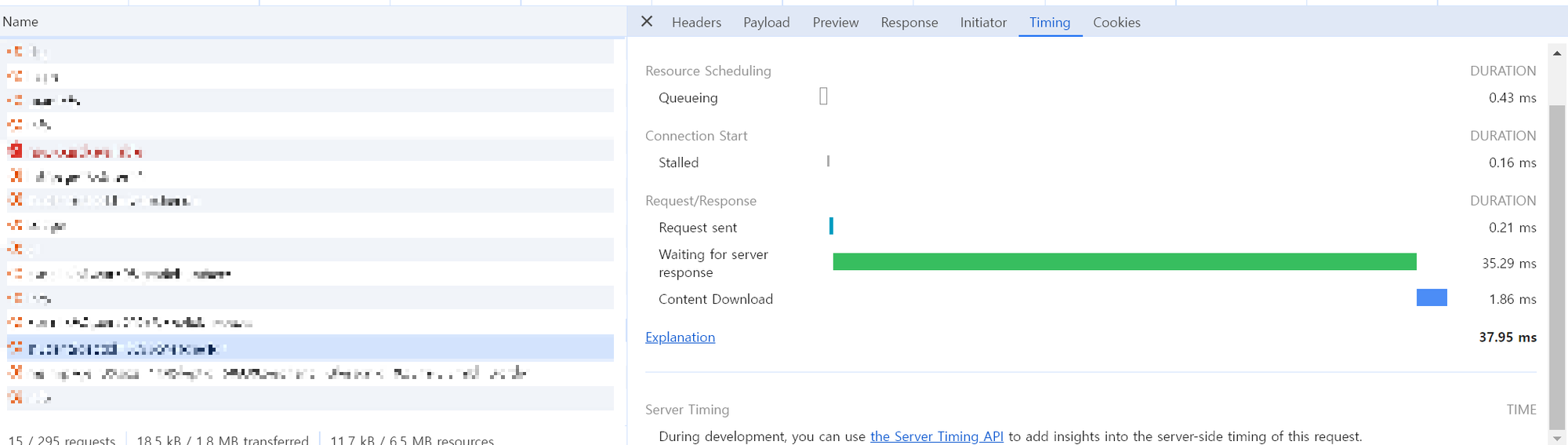
개발서버에서 테스트 한 결과, 1.12s -> 37.95ms 약 29배 속도 향상되었다.